Python has become the most widely used programming language today and the first choice for solving tasks in the field of data science. Python is an excellent choice for both amateurs and experts due to its ease of learning. Some of the reasons that make Python so popular for data science are that it is an open source, object-oriented, and high-performance language.
But the biggest advantage of Python for data science is the large variety of libraries that can help developers solve different problems. Let’s take a look at the 10 best Python libraries for data science:
TensorFlow
Topping our list of the 10 best Python libraries for data science is TensorFlow, developed by the Google Brain team. TensorFlow is a great choice for both beginners and professionals, and offers a wide range of flexible tools, libraries and community resources.
The library is focused on high-performance numerical calculations and has about 35,000 comments and a community of over 1,500 contributors. Its applications are used in various scientific fields, and its framework lays the foundation for defining and executing computations involving tensors, partially defined computational objects that ultimately produce value.
TensorFlow is particularly useful for tasks such as speech and image recognition, text applications, time series analysis, and video detection.
Here are some of the key features of TensorFlow for data science:
- It reduces errors by 50 to 60 percent in neural machine learning
- Excellent library management
- Flexible architecture and framework
- It works on different computer platforms
SciPy
Another top Python library for data science is SciPy, a free and open source Python library used to perform high-level calculations. Like TensorFlow, SciPy has a large and active community with hundreds of contributors. SciPy is particularly useful for scientific and engineering calculations and provides a variety of easy-to-use and efficient routines for scientific calculations.
SciPy is based on Numpy and includes all functions, turning them into useful, scientific tools. SciPy excels at performing scientific and technical calculations on large data sets and is often used for multidimensional image processing, optimization algorithms, and linear algebra.
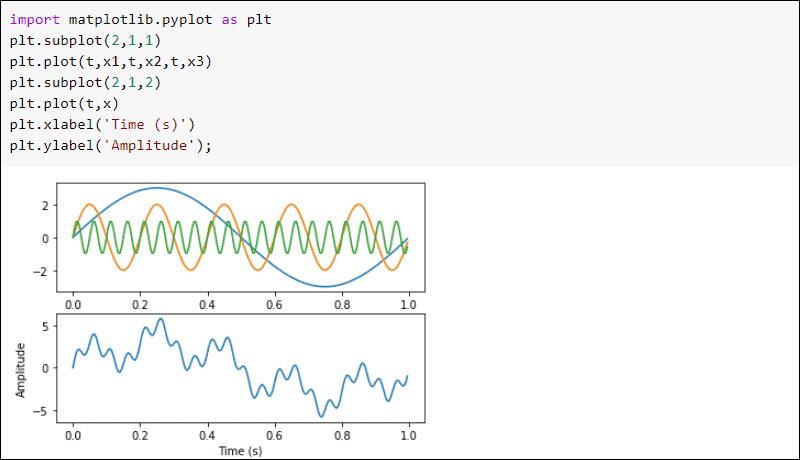
Here are some of the main features of SciPy for data science:
- High-level commands for data manipulation and visualization
- Built-in functions for solving differential equations
- Processing of multidimensional images
- Computing large data sets
Pandas
Another commonly used Python data science library is Pandas, which provides tools for data manipulation and analysis. The library contains its own powerful data structures for manipulating numeric tables and analyzing time series.
The two most important functionalities of the Pandas library are Series and DataFrames, which are fast and efficient ways to manage and explore data. These structures effectively represent data and allow manipulation in various ways.
Some of the main applications of the Pandas library include general data processing and data cleaning, statistics, finance, time interval generation, linear regression, and more.

Here are some of the main features of the Pandas data science library:
- Create your own function and apply it to data series
- High level abstraction
- High-level structures and manipulation tools
- Merge/link datasets
NumPy
NumPy is a Python library that can easily be used to process large multidimensional arrays and matrices. It uses a large set of high-level mathematical functions, which makes it particularly useful for efficient basic scientific calculations.
NumPy is a general-purpose array processing package that provides high-performance arrays and tools. It solves the inefficiency by providing multidimensional arrays, functions and operators that work efficiently with them.

This Python library is often used for data analysis, creating powerful multidimensional arrays, and serves as the basis for other libraries like SciPy and scikit-learn.
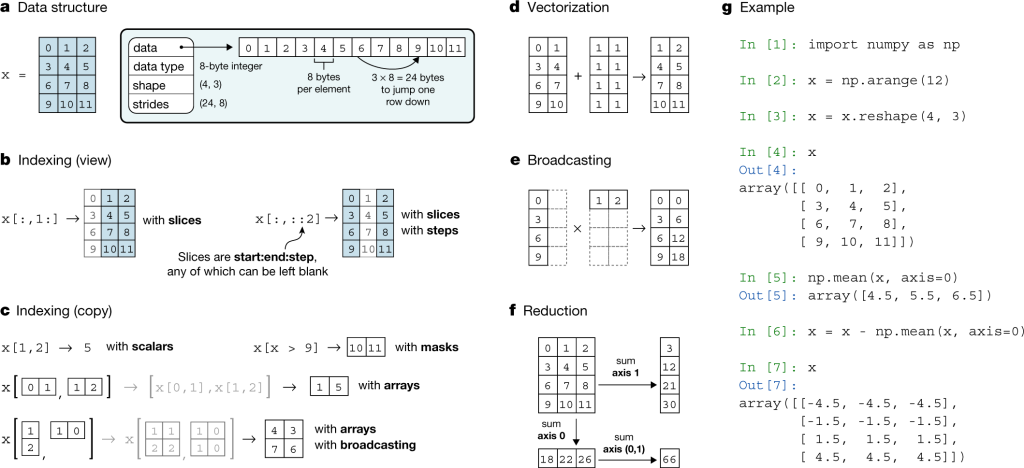
Here are some of the main features of the NumPy data science library:
- Fast, precompiled functions for numeric routines
- It supports an object-oriented approach
- Oriented to work with strings for more efficient computation
- Data cleaning and manipulation
Matplotlib
Matplotlib is a Python plotting library with a community of over 700 contributors. It enables the generation of graphs and diagrams that can be used for data visualization, as well as an object-oriented API for incorporating diagrams into applications.
One of the most popular choices for data science, Matplotlib has a variety of applications. It can be used to analyze correlations between variables, visualize model confidence intervals, and data distributions to gain insight, as well as detect outliers using a scatterplot.
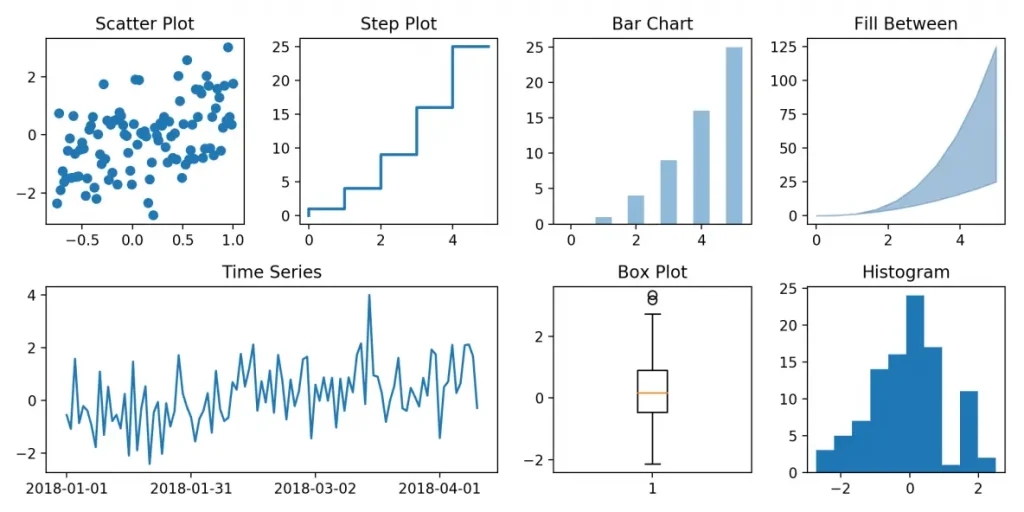
Here are some of the main features of the Matplotlib library for data science:
- It can be a replacement for MATLAB
- Free and open source
- It supports dozens of backends and output types
- Low memory requirements
Scikit-learn
Scikit-learn is another great Python library for data science. This machine learning library provides various useful machine learning algorithms and is designed to integrate with the SciPy and NumPy libraries.
Scikit-learn includes algorithms such as gradient boosting, DBSCAN, random forests under classification, regression, clustering and support vector machines methods.
This Python library is often used for applications such as clustering, classification, model selection, regression, and dimensionality reduction.
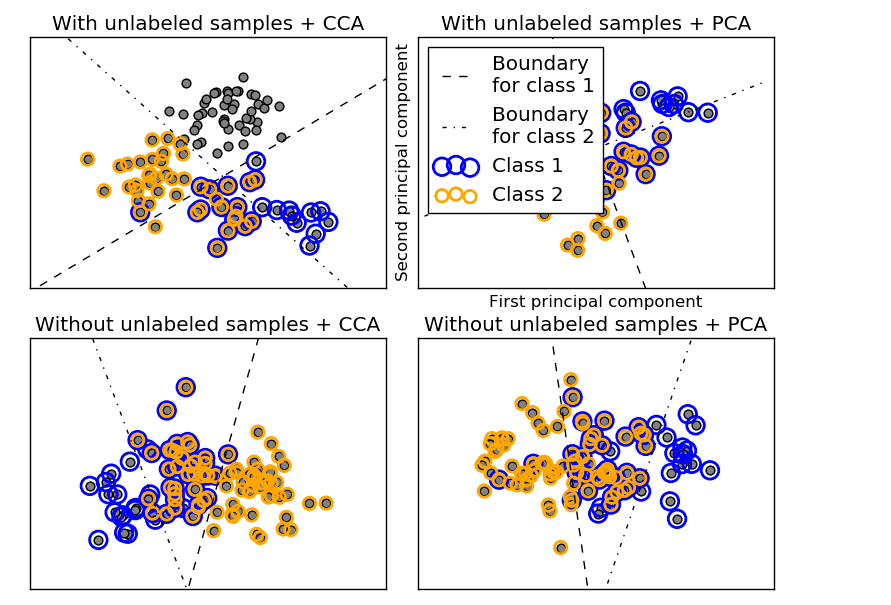
Here are some of the main features of the Scikit-learn data science library:
- Data classification and modeling
- Data preprocessing
- Model selection
- Machine learning algorithms from start to finish
Hard
Keras is an extremely popular Python library that is often used for deep learning and neural network modules, similar to TensorFlow. The library supports TensorFlow and Theano backends, making it a great choice for those who don’t want to mess around with TensorFlow too much.
This open library provides all the tools needed for model construction, data set analysis, and graph visualization. It also includes pre-labeled datasets that can be directly imported and loaded. The Keras library is modular, extensible and flexible, making it a user-friendly option for beginners. In addition, it offers one of the widest ranges of data types.
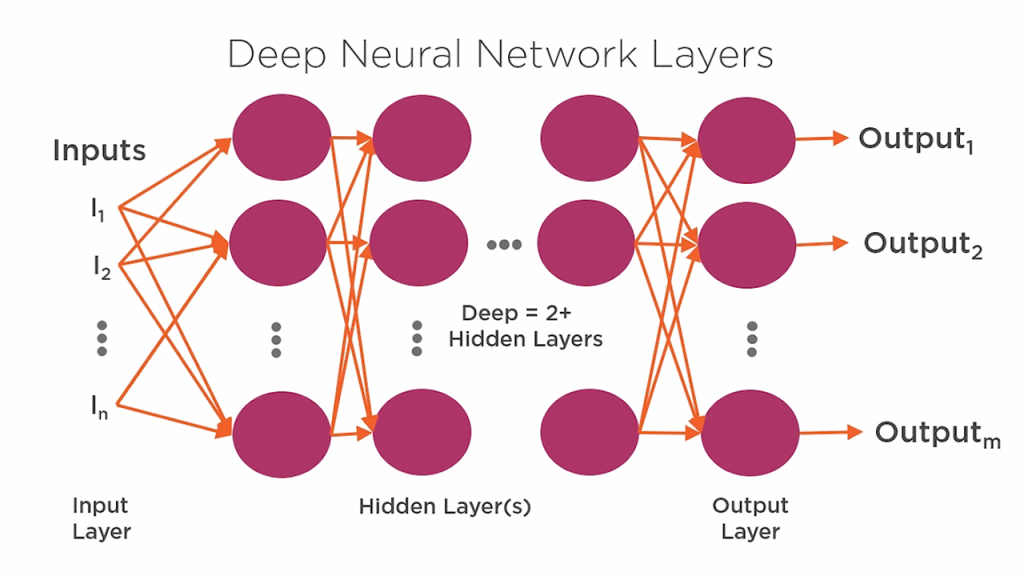
Keras is often sought after for its deep learning models that come with pre-trained weights and can be used to make predictions or extract features without having to build or train your own model.
Here are some of the key features of the Keras data science library:
- Development of neural layers
- Grouping of data
- Activation and cost functions
- Deep learning and machine learning models
Scrapy
Scrapy is one of the most famous Python libraries for data science. This fast and open-source web crawler framework is often used to extract data from web pages using XPath-based selectors.
This library has a wide range of applications, including building search programs that collect structured data from the web. It is also used to collect data through APIs and allows users to write universal, reusable code to build and scale large browsers.
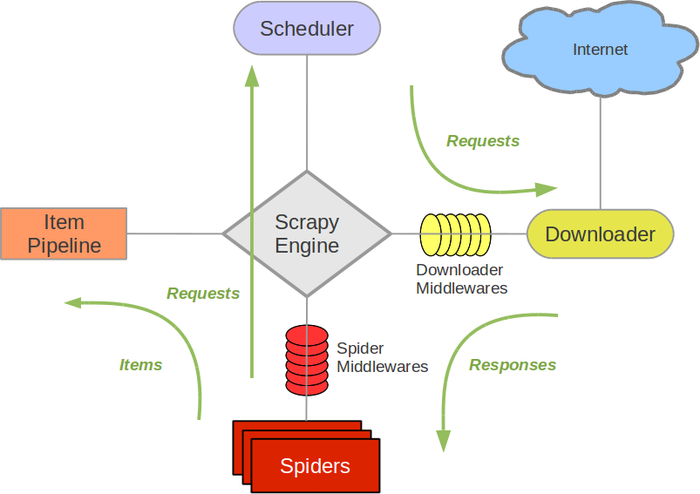
Here are some of the main features of the Scrapy data science library:
- Lightweight and open source
- A robust library for web browsing
- Extracting data from web pages using XPath-based selectors
- Built-in support
PyTorch
Nearing the end of our list is PyTorch, another top Python library for data science. This Python-based scientific computing package relies on the power of graphics processing units (GPUs) and is often chosen as the platform for deep learning research with maximum flexibility and speed.
Created by Facebook’s AI research team in 2016, PyTorch’s best features include high execution speed, which it achieves even when processing heavy graphs. It is extremely flexible, capable of running on simplified processors or central processing units (CPUs) and graphics processing units (GPUs).
Here are some of the main features of PyTorch for data science:
- Control over data sets
- High flexibility and speed
- Development of deep learning models
- Statistical distribution and operations
BeautifulSoup
Rounding out our list of the 10 best Python libraries for data science is BeautifulSoup, which is most commonly used for web browsing and data collection. With BeautifulSoup, users can collect data available on web pages without a proper CSV or API. At the same time, this Python library helps in collecting data and organizing it in the desired format.
BeautifulSoup also has an established support community and comprehensive documentation that makes learning easy.
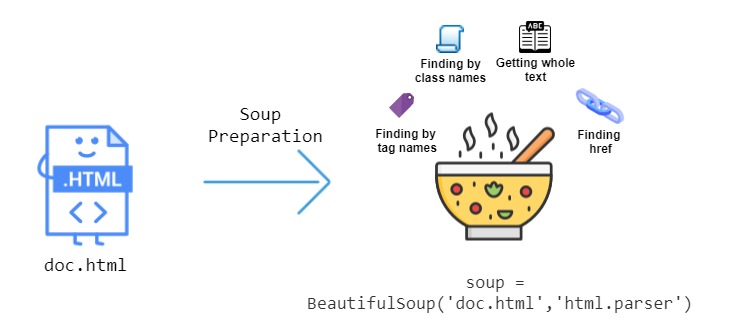
Here are some of the main features of the BeautifulSoup data science library:
- Community support
- Web browsing and data collection
- Simple to use
- Collecting data without a proper CSV or API
10 Best Python Libraries for Data Science was last modified: Jul 26th, 2024 by
Source: www.itnetwork.rs