In artificial intelligence computing, one of the most significant limiting factors is the memory capacity of the GPU, in addition to the computing power alone.
The amount of memory used by graphics cards has become a topic of much discussion with the rise of artificial intelligence. Now the Korean startup Panmnesia offers a unique solution to the problem.
Panmnesia has developed a solution that utilizes the CXL bus (Compute Express Link) for the memory shortage of graphics cards in artificial intelligence computing. Memory extensions suitable for the CXL bus are not new in themselves, but until now they have been aimed at increasing the central memory. The CXL bus uses the same physical bus as PCI Express, but with its own protocols.
Although CXL memory extensions are familiar elsewhere, they are not supported on the graphics card side, and the memory controllers of current graphics cards do not recognize possible extensions, except through Unified Virtual Memory, in which case only one large memory space is visible for the entire system. However, the problem with UVM is its slowness.
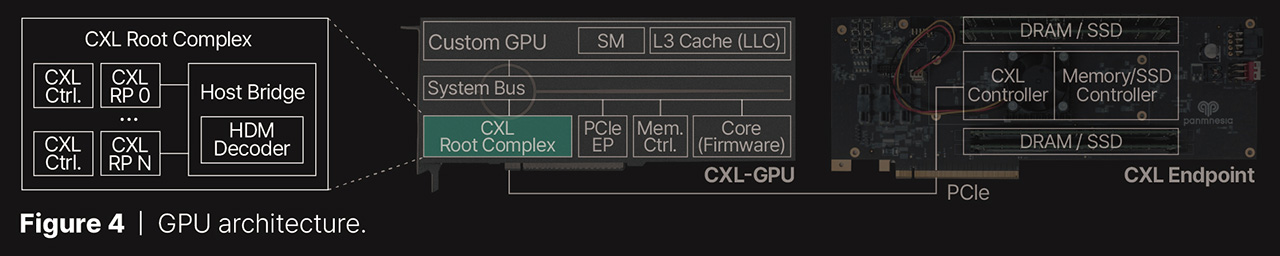
Because of this, Panmnensia developed its own “root complex” that supports memory expansions according to the CXL 3.1 standard, which connects the device behind it to other devices. A multi-ported root complex connects the GPU to the memory extensions and the Host-managed Device Memory or HDM decoder between them, which “tricks” the GPU into thinking that the memory behind it is main memory, although in reality it is clearly faster and at the end of a faster bus. According to a report from Tom’s Hardware, Panmnesia’s system only has double-digit nanosecond latencies, something between 10 and 99 nanoseconds. Both DRAM memories and NVMe drives can be used for memory expansion.

The tests done with CXL’s open-source prototype GPU included the UVM mode mentioned earlier in the news, apparently Samsung and Meta’s “CXL-Proto” and Panmnesia’s “CXL-Opt”. According to the tests, on the IPC side, CXL-Proto was 65% and CXL-Opt up to 222% faster than UVM. Correspondingly, the execution time of the kernel was clearly shortened, but without more precise figures it is impossible to evaluate what the readings that contradict the mathematics actually tell.
Panmnesia technology seems like a godsend for many AI tasks, but before it can be implemented, AMD, Intel and NVIDIA should implement support for CXL memory extensions.
Source: Tom’s Hardware
Source: www.io-tech.fi