my_recent_likes_cleaned
unnest_wider(post_data, names_sep = "_", names_repair = "unique") |>
unnest_wider(embed_data, names_sep = "_", names_repair = "unique") |>
unnest_wider(embed_data_external, names_sep = "_", names_repair = "unique")
This creates a data frame (tibble) with 40 columns. Select the desired column, rename it, and add a TimePulled timestamp column for later use.
my_recent_likes_cleaned select(Post = text, By = author_handle, Name = author_name, CreatedAt = post_data_createdAt, Likes = like_count, Reposts = repost_count, URI = uri, ExternalURL = embed_data_external_uri) |> mutate(TimePulled = Sys.time() )
It would also be useful to have a column containing the URL of each liked post. The existing URI column is at://did:plc:oky5czdrnfjpqslsw2a5iclo/app.bsky.feed.post/3lbd2ee2qvm2rIt has the same form as But the post URL is portion of the URI} Use syntax.
The following R code creates a URL column using the URI and By columns and adds a new PostID column for the URI portion used in the URL.
my_recent_likes_cleaned
mutate(PostID = stringr::str_replace(URI, "at.*?post\\/(.*?)$", "\\1"),
URL = glue::glue(" )
I usually save data like this as a Parquet file using the rio package.
rio::export(my_recent_likes_cleaned, "my_likes.parquet")
You can save data in various formats, such as .rds files or .csv files, by simply changing the file extension in the file name.
3step. Keep your Blue Sky ‘Likes’ file updated
It’s nice to keep your ‘likes’ collection as a snapshot of a single point in time, but it needs to be continuously updated to be useful. There may be other, more advanced methods, but a simple method is to load old data, import new data, then find rows that are not in the old data frame and add the old data.
previous_my_likes
Then, run all the code above, up to saving the ‘Like’, to retrieve the latest ‘Like’. Change the limit according to each person’s ‘like’ activity level.
my_recent_likes
unnest_wider(post_data, names_sep = "_", names_repair = "unique") |>
unnest_wider(embed_data, names_sep = "_", names_repair = "unique") |>
unnest_wider(embed_data_external, names_sep = "_", names_repair = "unique") |>
select(Post = text, By = author_handle, Name = author_name, CreatedAt = post_data_createdAt, Likes = like_count, Reposts = repost_count, URI = uri, ExternalURL = embed_data_external_uri) |>
mutate(TimePulled = Sys.time() ) |>
mutate(PostID = stringr::str_replace(URI, "at.*?post\\/(.*?)$", "\\1"),
URL = glue::glue(" )
Find new ‘likes’ that do not already exist in existing data.
new_my_likes
Combine new and old data.
deduped_my_likes
Finally, save the updated data by overwriting the old file.
rio::export(deduped_my_likes, 'my_likes.parquet')
4step. View and search data in a convenient way
We want to make this data available in a searchable table. At the end of each post’s text, we include a link to Blue Sky’s original post, making it easy to see any images, comments, parent items, or threads that aren’t in the post’s regular text. Also remove some unnecessary columns from the table.
my_likes_for_table
mutate(
Post = str_glue("{Post} >>"),
ExternalURL = ifelse(!is.na(ExternalURL), str_glue("{substr(ExternalURL, 1, 25)}..."), "")
) |>
select(Post, Name, CreatedAt, ExternalURL)
Here’s how to create a searchable HTML table of this data using the DT package.
DT::datatable(my_likes_for_table, rownames = FALSE, filter="top", escape = FALSE, options = list(pageLength = 25, autoWidth = TRUE, filter = "top", lengthMenu = c(25, 50, 75, 100), searchHighlight = TRUE, search = list(regex = TRUE) ) )
At the top right of this table, there is a table-wide search box and a search filter for each column, allowing you to search for two search terms in the table. For example, you can search for the #rstats hashtag in the main search bar, then search for posts containing LLM in the post column filter pane (table searches are case insensitive). or search = list(regex = TRUE)Optionally, regular expression search is enabled, so in the search box (?=.rstats)(?=.(LLM)) Only one forward search pattern can be used.
IDG
Generative AI chatbots such as ChatGPT and Claude are very good at writing complex regular expressions. Turning on matching text highlighting in the table makes it easy to check whether your regular expression is working as you want.
LLMQuery Blue Sky ‘Likes’ with
The simplest and free way to query these posts using generative AI is to upload a data file to the service of your choice. In my case, I got good results with Google Notebook LM. Notebook LM is free and shows the source text used in the answer. The file limit is also generous, 500,000 words or 200MB per source. Additionally, Google says it does not use user data for LLM learning.
The query “Stories about R packages with science-related color palettes” retrieved exactly the items I had previously liked and reposted. There was no need to write a prompt or give instructions to the NotebookLLM to let them know that 1) they would only use that document in their response and 2) they would like to see the source text used to generate the response. I was just asking a question.
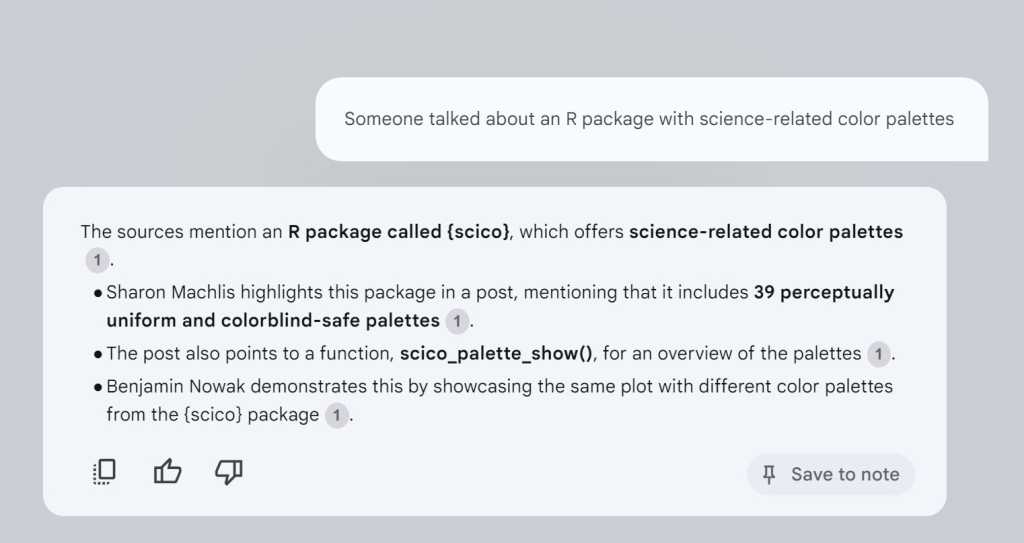
IDG
To make the data more useful and reduce waste, we limited CreatedAt to dates without time, kept post URLs in a separate column (instead of clickable links with HTML appended), and removed the External URL column. This concise version was saved as a .txt file rather than a .csv file. This is because Notebook LM cannot handle the .csv extension.
my_likes_for_ai mutate(CreatedAt = substr(CreatedAt, 1, 10)) |> select(Post, Name, CreatedAt, URL) rio::export(my_likes_for_ai, "my_likes_for_ai.txt")
After uploading the ‘Like’ file to Notebook LM, you can start asking questions as soon as the file is processed.

IDG
If you want to query documents within R without using an external service, one way is to use the GitHub project: Elmer Assistantis to use . You can easily modify the prompt and source information to suit your needs. However, it was difficult to run Elmer Assistant locally even on a Windows PC with decent performance.
Schedule an auto-run script to update ‘likes’
For this to be useful, the “Posts I Liked” data needs to be kept up to date. In my case, I run the script manually on my local computer when using Blue Sky, but you can also schedule the script to run automatically on a daily or weekly basis. Here are three ways:
- Run script locally. If you’re not too worried about your script always running on the correct schedule, you can always go for Windows. taskscheduleRor for Mac or Linux chronR You can use the same tool to automatically run R scripts.
- Using GitHub Actions. Johannes Gruber, who created the atrrr package, Using free GitHub Actions This explains how to run the R Blogger Blue Sky bot. You can modify these instructions to fit other R scripts.
- Run script on cloud server. Digital OceanThere is also a way to use a cron job together with an instance of a public cloud such as .
Add bookmarks and note columns using spreadsheets or R tools
Maybe you need Blue Sky like data, but don’t want it to include every post you’ve liked so far. This may be the case if you click ‘Like’ simply to encourage the author, or if you click ‘Like’ because the post is interesting, but you will never come back to it again later.
There is something to be careful about. If someone likes a lot of posts and wants to keep their data up to date, manually marking each bookmark in a spreadsheet can be tedious. Instead of creating a selective subset of “bookmarks,” you could search the entire database of likes.
The process I am using is as follows: For initial setup, we recommend using Excel or .csv files.
1step. Import ‘Likes’ into a spreadsheet and add a column
First, import the my_likes.parquet file, add empty bookmark and note columns, and then save it as a new file.
my_likes
mutate(Notes = as.character(""), .before = 1) |>
mutate(Bookmark = as.character(""), .after = Bookmark)
rio::export(likes_w_bookmarks, "likes_w_bookmarks.xlsx")
In my case, after some experimentation, I created a bookmark column with letters so that I could add a “T” or “F” to the spreadsheet rather than a logical TRUE or FLASE column. By using characters, you don’t have to worry about whether R’s Boolean fields will be converted appropriately when you use this data outside of R. In the Notes column, you can add text explaining why you want to find something again.
The next step, the manual part of this process, is to mark the likes to keep as bookmarks. If you open it in a spreadsheet, it is convenient because you can click F or T and drag it to multiple cells at the same time. If you have a lot of likes, it will be a tedious task. For now, you can mark them all with “F” and use manual bookmarking in the future to ease the burden.
Manually save the file again as likes_w_bookmarks.xlsx.
2step. Keep your spreadsheets and likes in sync
After this initial setup, it’s a good idea to keep your spreadsheet in sync with your data as it updates. One way to implement this is as follows:
Update the new deduped_my_likes ‘like’ file, then create a bookmark confirmation query and combine it with the deduplicated ‘like’ file.
bookmark_check select(URL, Bookmark, Notes) my_likes_w_bookmarks relocate(Bookmark, Notes)
A file combining new ‘like’ data and existing bookmark data is created, and there are no bookmark or memo items at the top yet. Save it as a spreadsheet file.
rio::export(my_likes_w_bookmarks, "likes_w_bookmarks.xlsx")
An alternative to this manual and somewhat cumbersome process is to store the de-duplicated ‘Likes’ data in a frame. dplyr::filter()You can use it to remove items you won’t find again (for example, posts mentioning your favorite sports team, or posts about a specific date that only made sense at the time).
next steps
If you want to search for posts written directly by users, use atrrr. get_skeets_authored_by() You can use functions to import them through the Blue Sky API following a similar workflow. Once you get on this path, you’ll discover that you can do much more, and you’ll meet other R users on the same path.
dl-itworldkorea@foundryco.com
Source: www.itworld.co.kr