Model validation is a key step in any machine learning task. It involves checking how well the model works on unseen data. This ensures that the model’s predictions are reliable, accurate and useful in real-world situations. Skipping validation may mean implementing a model that overfits the training data or does not perform well in practical applications.
Why is model validation important?
Model validation has two main purposes: to ensure that the model works well on new data and to check that it is not biased or overfitting to the training data set. Overfitting occurs when a model learns patterns specific to the training data, which can reduce its effectiveness when applied to new data sets. On the other hand, underfitting occurs when the model is too simple and misses key patterns in the data.
By validating a model, you can review its effectiveness on different data sets, allowing for optimization for real-world use. In industries such as healthcare, finance, and autonomous vehicles, validation is critical because errors in predictions can lead to significant problems, such as financial losses or security risks.
Common techniques for model validation
There are several methods that can be used to validate a machine learning model, each with its own advantages depending on the situation. Here are some commonly used techniques:
Data set split (Train-Test Split)

One of the simplest ways to validate a model is to split the data set into a training set and a test set. This is usually done in an 80-20 ratio, where 80% is used for training and the remaining 20% for testing. This approach, however, may be less reliable if the dataset is too small, as the test set may not fully reflect the extent of the data.
Cross-Validation
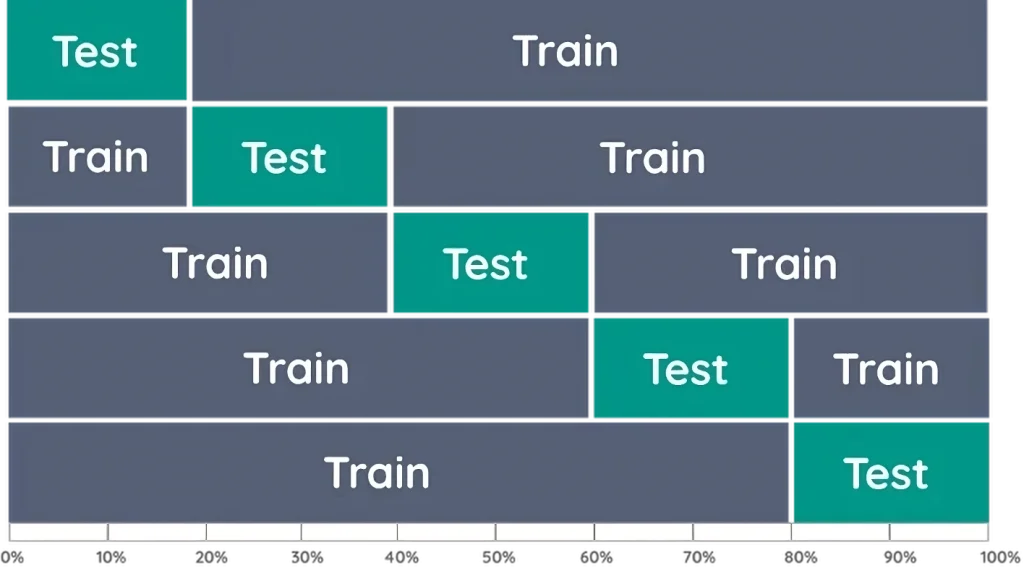
Cross-validation is a more powerful method. In this technique, the data set is divided into several parts, called “folds.” In k-fold cross-validation, the data is divided into k different parts. Each time, one segment is reserved for testing, while the model is trained using the remaining k-1 segments. This process is repeated k times, so that each part is used as a test set once. This method provides a more comprehensive assessment of model capability.
Stratified K-Fold Cross-Validation
This method ensures that each fold reflects the balance of classes found in the entire data set. It is especially useful when working with unbalanced data, such as fraud detection or medical diagnostics, where one class may be significantly more frequent than others.
Bootstrapping
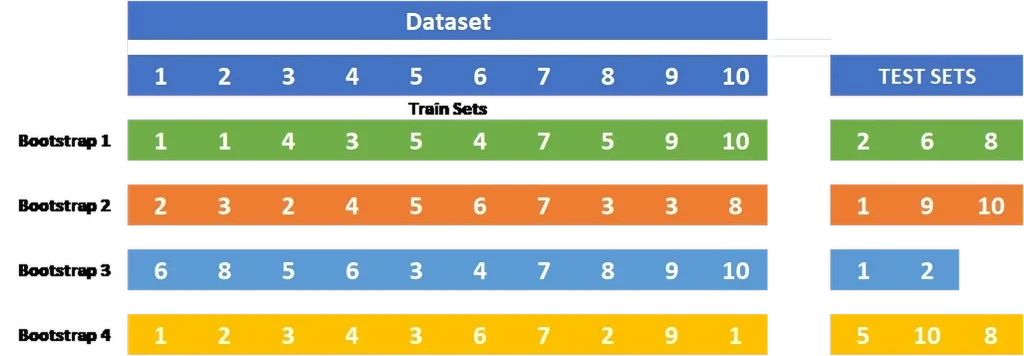
Bootstrapping is another method, in which random samples are taken from the data multiple times with return. This approach helps in measuring the accuracy of the model and understanding the variability of its performance across different samples. It can be especially useful for smaller datasets.
Performance metrics for validation
Choosing the right metrics to evaluate model performance is critical. Different metrics are chosen depending on the task. For example:
- Accuracy: A measure of the percentage of correct predictions. Although simple, it can be misleading when dealing with unbalanced data.
- Accuracy and Sensitivity: Accuracy refers to the fraction of positive predictions that are correct. Sensitivity reflects the percentage of true positives that are correctly identified. These metrics are essential in situations like spam filtering or medical diagnostics, where the costs of false positives and negatives differ.
- F1 result: Combines precision and sensitivity using their harmonic average. It is useful when it is important to balance both metrics.
- Mean Squared Error (MSE): Common in regression problems, MSE finds the average of the squared errors between predicted and actual values.
Challenges in model validation
Model validation can face several challenges. One common problem is data leakage, where information from the validation set unintentionally affects the training process. This leads to performance estimates that are too optimistic. Another problem is data change, which occurs when data characteristics change over time. If this happens and is not monitored, the model may become less effective.
Conclusion
Model validation plays a key role in ensuring that machine learning models are accurate and effective when applied in real-world settings. It helps to avoid overfitting, identify bias and check that the model works well on unseen data.
Techniques such as splitting the data set into a training and test set, cross-validation and bootstrapping enable thorough testing of the model, revealing strengths and areas for improvement. By choosing the appropriate validation methods and metrics, you ensure that the model meets the standards. Continuous monitoring after implementation is essential, especially when data changes over time.
The post What is model validation in machine learning? appeared first on ITNetwork.
Source: www.itnetwork.rs